0. 写在前面
要说NLP最近最火的是什么,那必是BERT无疑了。强悍如BERT,在十多项NLP的任务上强势屠榜,业界声称BERT将开创NLP领域新的纪元。在BERT刚出来的时候,就在各种公众号上看过各种原理解释,但一直没有去认真研究论文。后来在PaperWeekly公众号上阅读了万字长文《NLP的巨人肩膀》,算是把BERT的诞生史过了一遍。在看这篇文章的过程中发现Word2Vec到BERT中间的那么多演变自己都没有好好研究过,于是打算写BERT发展史系列文章,从传统的词嵌入开始,详细讲解词嵌入往BERT发展的过程及其中的思想的演变过程。这一系列涉及到很多算法,基本上涵盖了大部分比较重要的NLP技术和思想,有些是我接触过的,有些我还没有接触过,因此也希望写作的过程能够push自己去学习,去进步。
我希望在这一系列文章中尽量以自己的话语阐述各个算法背后的思想和原理,多输出一些自己的理解,并在最后附上我个人认为学习这些算法比较好的材料和教程。如果看我的文章没有太理解,也可以多去看看参考材料。
1.机器学习流程
什么是机器学习?抛开严肃的定义,在我看来,机器学习(这里特指有监督学习)就是使用计算机对事件的结果进行建模的过程。用数学符号来表示就是$f(x)->y$,其中$y$代表事件的结果,$x$代表影响事件结果的各个因素,f代表我们使用的机器学习算法。即,我们希望将事件结果与影响结果的因素以某种函数的形式映射起来。
比如,主人公算法小白菜现在在上小学五年级,我们要预测他在期末考试中能否及格。事件的结果就是能及格和不能及格,影响事件结果的因素则有很多,这些因素有的对预测结果很重要,有的则无关紧要。比如算法小白菜在每次月考中的成绩,对于预测就很重要,而算法小白菜的身高则无关紧要。机器学习中,挖掘影响事件结果因素的过程称为特征工程,这一步的目的是依据现有数据挖掘出对结果有影响的因素(也叫特征),然后使用这些特征对结果进行建模。
因此,一个大致的数据挖掘流程为:数据预处理—>特征工程—>建模。很多时候,挖掘和发现出好的特征对最后结果的影响甚至要大于模型本身。
其实说了这么多,我只是想说明,好的特征对于建模的重要性。就像我们这世界有果皆有因,一件事情发生的背后,定有各种因素在背后支撑。我们希望计算机能够帮助我们建立各种因素取值和事件结果的对应关系,但在此之前,如何确定这些因素则是个让人头疼的东西。
2. 词嵌入
在互联网中,我们每天都会接触到海量的文本信息。所谓NLP,就是使用计算机处理自然语言的过程。而我们都知道,计算机只能处理数值,因此自然语言需要以一定的形式转化为数值。词嵌入就是将词语(word)映射为数字的方式。一个单纯的实数包含的信息太少,一般我们映射为一个数值向量。这时我们会发现一个问题,怎么把词语转换为数值向量?自然语言本身蕴含了语义和句法等特征,如何在转换过程中保留这些抽象的特征?这点其实很重要,因为如果没有将自然语言的特征很好的保留下来,后续的所有工作就是对一些无意义的信息进行建模,自然得不到好的结果。纵观NLP的发展史,很多革命性的成果都是词嵌入的发展成果,如Word2Vec、ELMo和BERT,其实都是很好地将自然语言的特征在转换过程中进行了保留。
接下来我会以例子的形式介绍几个基于频率的词嵌入方法。
2.1 词频向量
比如我们有两个文档(Document):
D1:我 叫 算法 小 白菜 。我 很 懒惰 。
D2:算法 小 白菜 是 一个 懒惰 的 人 。
这里已经对句子进行了分词,即将各个句子拆分为词语的组合,词语之间用空格隔开。
这两篇文档包含的所有非重复词构成一个词典(dictionary):{“我”,“叫”,“算法”,“小”,“白菜”,“。”,“很”,“懒惰”,“是”,“一个”,“的”,“人”}。
这样每篇文档中词典中词语出现的频率如下表所示:
| 我 | 叫 | 算法 | 小 | 白菜 | 。 | 很 | 懒惰 | 是 | 一个 | 的 | 人 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
| D2 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
D1行“我”列的数值为2代表在文档D1中,“我”这个词出现了两次。现在我们通过以上表格得到了一个词频矩阵。我们可以使用列向量来表示一个词语,比如使用[2,0]来表示“我”这个词;使用行向量来表示一篇文档,比如使用[2,1,1,1,1,2,1,1,0,0,0,0]来表示文档D1。
OK,以上就是使用词频向量进行词嵌入的过程。但在实际使用过程中许多细节会有变种。比如词典的组织方式。在真实世界中,我们的语料数据通常是包含数十万到上百万篇文档的,这些文档包含的非重复词会非常多。而每篇文档包含的词语数量相对于词典中的词语数量是非常小的,这会导致词频矩阵中会出现非常多的0。所以组织词典的另外一个方式是按词语出现的频率排序,选择频率最高的前1000个词语组成词典。
2.2 TF-IDF向量
首先思考下词频矩阵有什么局限性。比如一篇关于游戏的文章,游戏这个词的词频会比较高,但像“的”、“和”这种通用词(NLP中叫停用词)出现的频率也非常高。从特征的角度出发,游戏这个词对这篇文章来说是个重要特征,“的”、“和”这种词则是不重要的特征,但词频矩阵这种词嵌入方式的结果却给予了这两种特征相似的重要性。
TF-IDF(词频-逆文档频率)可以通过给予通用词较小的计算权重来解决这个问题。继续看例子。
我们有两篇文档D1和D2,每篇文章中所包含的词语及其词频如下图所示:

TF的定义如下:
TF = (词语w在一篇文档中出现的次数)/(文档中的词语总数)
根据这个定义,可以计算TF(关于,D1) = 1/9;TF(学习,D2) = 3/9。
TF表示的是该词语对于该文档的贡献程度,我们认为与文章相关的词语出现的频率应该会比较高。
IDF的定义如下:
IDF = log((文档的数量)/ (包含词语w的文档数量))
根据这个定义,得到IDF(关于) = log(2/2) = 0;IDF(游戏) = log(2/1) = 0.301。
IDF想表达的是,如果一个词语在大部分甚至所有文档中都出现(词语中的中央空调),那么这个词语对于任意一篇文档都是不重要的。
最后,TF-IDF的计算方式就是把TF和IDF相乘即可。来看一下:
TF-IDF(关于,D1) = (1/9)* 0 = 0
TF-IDF(游戏,D1) = (3/9) * 0.301 = 0.1003
TF-IDF(学习,D2) = (3/9)* 0.301 = 0.1003
这下就比较符合我们的直觉了:重要的词语(特征)应该具有更高的权重。
将词频矩阵中的词频值替换为TF-IDF值,我们就可以得到文档和词语的向量表示了。同时,由于TF-IDF的特征,TF-IDF还经常被用来提取文章中的关键词。
2.3 词共现向量
这个方法的出发点是:相似的词语会经常同时出现,并且具有相似的上下文。比如:苹果是水果。香蕉是水果。苹果和香蕉具有相似的上下文。
在深入词共现矩阵的构造和定义之前,我们先来介绍两个概念:共现和上下文窗口。
共现 — 对于给定的语料,共现指词语w1和词语w2在给定上下文窗口中共同出现的次数。
上下文窗口 — 计算共现时所指定的窗口大小,由距离和方向指定。
同样以一个例子来说明:
Corpus = He is not lazy. He is intelligent. He is smart.
给定距离2和双向的上下文窗口,该例的词共现矩阵如下:
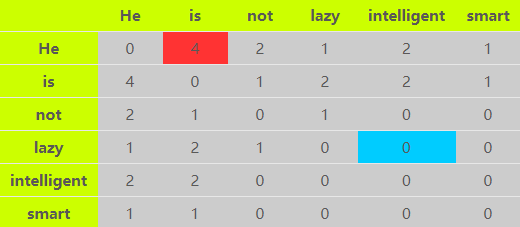
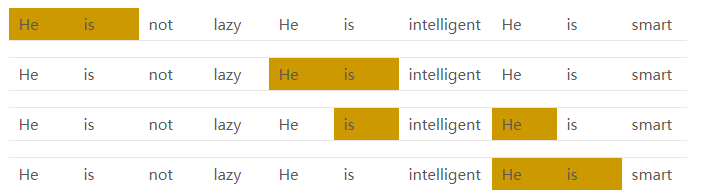
以图中的红色框和蓝色框为例。红色框表示“He”和“is”的共现次数为4,如下图所示:
而蓝色框值为0,代表词“lazy”从未出现在词“intelligent”的方圆两词之内。
在词共现矩阵中,我们可以使用行向量或者列向量来表示词语(矩阵是对称的)。但存在的问题与词频矩阵相似,向量的维度等于词典的大小V,这将导致向量是稀疏且高维的,不利于计算。在实际使用中,通常是使用PCA或SVD等技术,将词共现矩阵降维为V×k(k<<V)的大小,这样,每个词语将使用一个k维大小的向量来表示。
3. 几点想法
- 自然语言的特征是非常抽象的,如何将“苹果”这个词的语义以数值向量的方式体现出来是非常有挑战性的。词频向量和TF-IDF向量都是从词语和文档的关系角度出发的,从词语对文档的重要程度出发去完成词语/文档到向量的转换。而词共现矩阵则是从词语与词语之间的关系角度出发,设法抽取词语的含义。这给我们一种思路,单纯地考虑如何将某个词的语义映射到向量不太可能实现,那是否可以将词语映射到向量空间之后依然保留词语与词语之间的关系?
- 基于统计的词嵌入方法在什么样的任务中可以取得好的结果呢?同样从特征的角度出发,词频向量和TF-IDF向量提取的是词语对文档的重要性特征,什么样的任务需要这种特征呢?比如垃圾邮件识别,一些垃圾邮件一般有经常出现的“垃圾”词语,就可以使用基于统计的词嵌入方法;比如关键词提取,就可以使用TF-IDF。而一些需要复杂语义和句法特征的任务,如机器阅读理解,机器翻译等,就无法使用这些词嵌入方法。
- 之前被面试官问到过一个问题:基于统计的词嵌入方法和基于预测的词嵌入方法(如Word2Vec)有什么区别,为什么深度学习中要使用后者。个人观点是,一个方面,基于统计的词嵌入方法一旦在数据确定之后,词的向量便就确定,在不同的NLP任务中都要使用相同的词向量,无法根据不同任务进行调整。而基于预测的词嵌入可以在不同的任务和模型中更新词向量,使词向量逐步地适应这项任务;另一方面则是基于统计的词嵌入方法提取的语义信息实在太少,无法取到比较好的结果。
4. 参考资料
An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec
