0. 写在前面
上一篇文章中主要介绍了基于统计方法的词嵌入,这些方法都是使用很长的向量来表示一个词语,且词语的“含义”分布在高维度向量的一个或少数几个分量上(稀疏)。这些方法的主要问题在于用于表示词语的向量维度过高且非常稀疏,并且无法很好的表征词语的含义。那么一个理想的词向量应该是什么样呢?
想象一下,我们身处于一个充满词语的空间,这个空间中,相似的词语们组成一个“家族”抱团取暖,它们的距离比较近;不相似的词语身处不同的“家族”,距离较远。如“我”“你”“他”“吴彦祖”这些词的在词空间的距离比较近,“香蕉”和“电脑”在词空间的距离比较远。那么词嵌入其实就是某种将词空间映射到向量空间的方法。我们希望这些词语映射到一个固定长度的稠密低维度(相对于词表大小而言)向量,且依然保持以上特性,可以使用向量之间的距离来度量词语之间的相似性,这就是Distributed Representation。这里谈一下“Distributed”这个词的含义。基于统计的词嵌入方法产生的向量非常稀疏,词语的含义集中分布在向量的一个或少数几个非零分量上。而“Distributed”其中文意思是“分布式”,意思是指将词语的语义均匀分布到向量的各个分量上, 每个非零分量都承担其一部分含义。
这篇文章的主角虽然是语言模型,但词向量与神经语言模型相伴相生,Word2Vec其实就是在神经语言模型的基础上改进发展而来的。所以理解好语言模型对理解Word2Vec也有很大帮助。
1. 语言模型
相信大家都用过或者听过小米智能印象或者天猫精灵,这类产品都用到了语音识别技术,即,将语音识别为自然语言文字。某天,LN不分的算法小白菜同学对着小爱同学说:
老(nao)奶奶(lailai)喝牛(liu)奶(lai)
语音识别技术将这句话转为文字有以下几种可能:
- 老来来喝牛奶
- 老奶奶喝刘奶
- 老奶奶喝牛奶
- ……
问题来了,这么多可能,选择哪个作为最终结果呢?当然是最合理的,或者说概率最高的。这几个句子中,3号句子在现实中存在的概率是最高的,所以我们选择3号作为最终识别的结果。而语言模型,就是用来计算一个句子出现概率的模型。对于上例来说,就是分别计算P(老,来来,喝,牛奶)、P(老,奶奶,喝,刘奶)和P(老,奶奶,喝,牛奶),取概率最大的句子作为结果。
2. 统计语言模型
我们可以将句子看做单词序列:$w_1、w_2……w_n$ 。那么语言模型的目标就是计算
ps. 以上公式可以通过条件概率和链式法则推得,也将句子的生成视作句子填充事件的链条直接得到。
对于上面的例子,就是计算P(老,奶奶,喝,牛奶) = P(老)*P(奶奶 | 老)*P(喝|老,奶奶)*P(牛奶|老,奶奶,喝)。
由此可以看出,求一个句子出现概率的核心是求各个词语出现的条件概率。
在统计语言模型中,该条件概率通过极大似然估计计算:
但以上方法存在两个问题:
- 要求的概率太多了,因为w1,w2….wn的组合实在太多了(n的词表数次方);
- 由于语料的数量有限,数据中可能不存在w1,w2,….wn的组合,导致求得的条件概率为0。
针对第一个问题,可以引入马尔科夫假设。这个假设很简单,就是假设任意一个词出现的概率只与它前面出现的有限n个词有关。引入马尔科夫假设的语言模型又叫n-gram语言模型。我们假设n=1,可以得到:
条件概率同样通过极大似然估计计算:
这样计算量就少了很多。
针对第二个问题,引入平滑技术。平滑技术的思想和目的是将数据集中看到的概率分配一点给未出现的数据(避免概率为0),并且保持总的概率和为1。这里就不细讲了。
这里讨论一下马尔科夫假设的合理性。为什么可以这样假设?首先这种假设的有效性肯定是经过实践验证的,这里想讨论的是直觉上的合理性。思考一下在写“老奶奶喝牛奶”这句话时,到写“牛奶”这个词的时候,我们更多关注的是“喝”这个词,我们思考(下意识)更多的是与“喝”这个词匹配的词,而非与“老奶奶喝”匹配的词。因此,引入马尔科夫假设虽然会损失一些信息,但确实能够进行对句子的概率进行近似,并且可以极大地方便计算。
上面提出了两个问题,这里从机器学习的角度理解一下其本质。将条件概率看做语言模型中的参数,问题一在于语言模型的参数太多了;问题二在于由于数据量有限,导致许多参数无法估计。即:相对数据量而言,模型太复杂了,也就是说模型过拟合了!一个简单的例子就是数据集中没出现的句子,该语言模型会将这个句子出现的概率计算为0(未引入n-gram和平滑之前)。即模型的泛化能力不够,无法处理没“见过”的句子。
针对问题一引入马尔科夫假设,就是降低模型复杂度;针对问题二引入平滑,则类似于引入了正则化,对参数进行了约束。这些都是机器学习中解决模型过拟合,提高模型泛化能力的方法。
求出所有的条件概率之后,针对一个新的句子,只需要将对应的条件概率连乘即可得到句子的概率了。
最后,继续思考一个问题:句子1:“A dog is running in the room”和句子2:”A cat is running in the room”两个句子哪个概率大一些?直觉上来说应该是相似的,但统计语言模型非常受数据集的影响,无法考虑词语与词语的相似度,所以以上两个句子的概率计算结果可能是相差很大的。比如数据集中句子1出现了100次,句子2只出现了1次,那最后的计算结果P(句子1)将远大于P(句子2)。下面介绍的前向神经网络语言模型能比较好地解决这个问题。
3. 神经网络语言模型
前面说过,语言模型的核心是求词语出现的条件概率。说起条件概率,其实机器学习中许多分类模型就是对给定输入x求结果y的条件概率进行建模的。那么,是否可以使用机器学习中的分类模型来对语言模型进行建模呢?机器学习中,一般是对问题构造一个目标函数,然后使用数据对目标函数进行优化,求得一组最优参数,然后使用这组参数对应的模型来进行预测。对于语言模型来说,可以将目标函数设置为:
其中C表示语料(Corpus),Contex(w)表示词w的上下文。由此可见,我们可以使用机器学习训练得到词语w 的上下文到词语w这个类别的映射关系。2003年,Bengio等人发表的《A Neural Probabilistic Language Model》论文中,使用前向神经网络表征了这种映射关系。
在介绍模型细节之前,我们先来捋一捋。我们需要训练的是一个全连接神经网络模型,输入是词语w前面的n个词语(上下文),输出是预测为所有词的概率,我们希望词语w对应的概率最大化。问题来了,词语w的上下文怎么输入神经网络?论文中的做法是使用随机初始化的方法建立一个|V|×k大小的查找表(lookup table),该表内的每一行向量唯一表示一个词语。
以“老 奶奶 喝 牛奶”作为语料库为例,我们可以得到一个大小|V|=4的词表:{“老”,“奶奶”,“喝”,“牛奶”}。为每个词编号,得到:{0: “老”, 1: “奶奶”, 2: “喝”, 3: “牛奶”}。假设每个词向量的维度为3,随机初始化一个4×3大小的矩阵(查找表)如下(这里是自己编的数字,实际是随机生成的服从一定分布的数字):
其中,[0.1,0.2,0.3]表示编号为0的词语“老”的词向量,以此类推。
以“老”、“奶奶”、“喝”预测“牛奶”为例(上下文长度为3),模型的结构图如下:
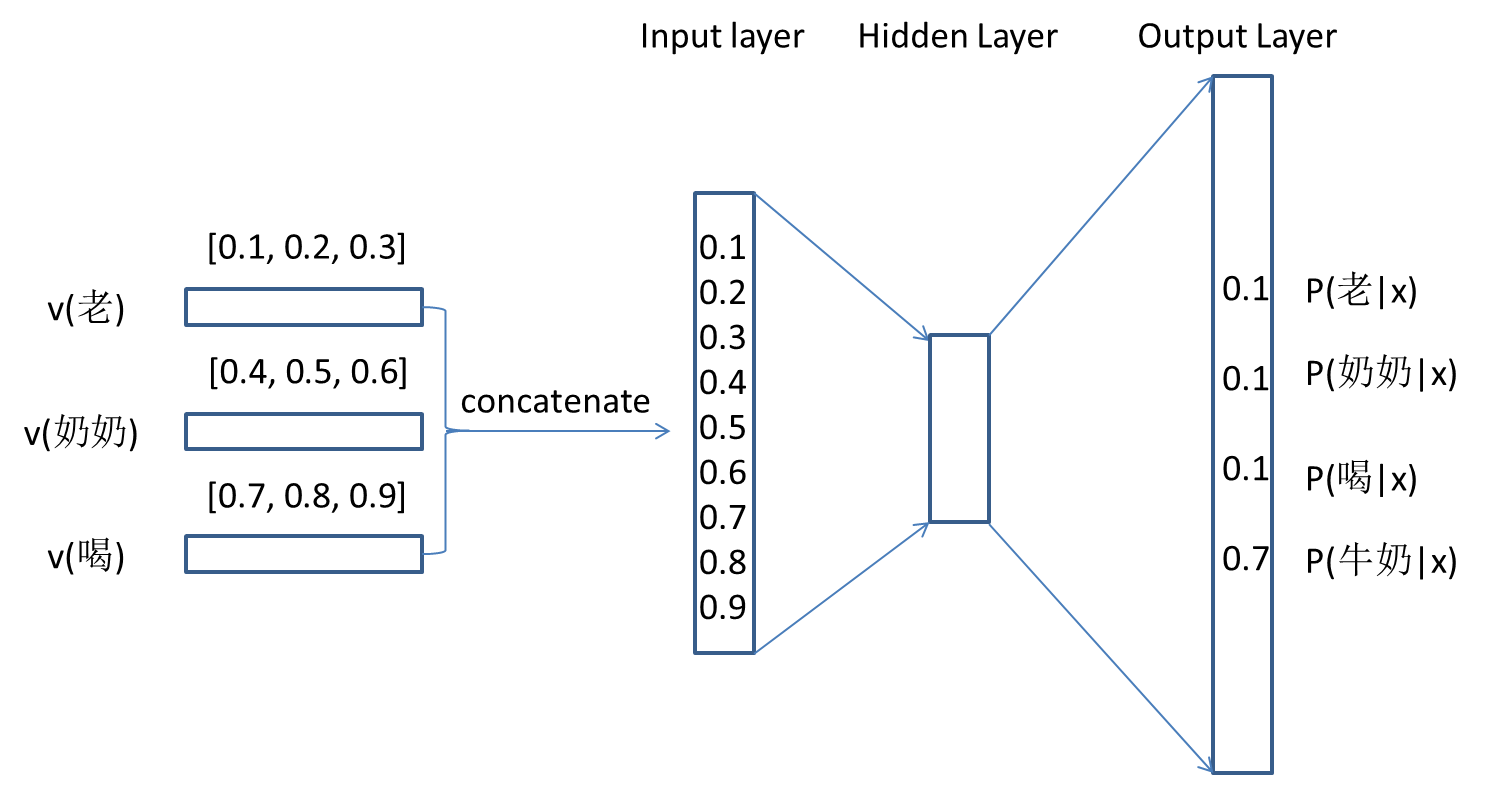
训练时,输入词去查找表中找到对应的词向量,然后将输入词的词向量拼接在一起,形成一个长度为3×k(k为词向量维度)的输入向量。经过一层隐层后,输出层使用softmax函数将输出映射到(0,1)中,输出层的数字表示输出为对应编号词语的概率。这个例子中,我们希望最大化输出层最后一个数字,代表P(牛奶|老,奶奶,牛奶)。注意,这个样本的训练过程只用到了上下文词语:“老”,“奶奶”,“喝”的词向量,没有用到“牛奶”的词向量。此外,需要注意的是,与通常的神经网络的输入都是已知的不同,我们之前初始化的矩阵查找表是和神经网络的参数同时训练更新的!
以上是一个样本的训练过程,如果我们的句子是“老 奶奶 喝 牛奶 和 咖啡”,我们还可以构造出另外的样本:((奶奶,喝,牛奶), 和),((喝,牛奶,和), 咖啡)。
通过这个方法训练的语言模型有什么优势呢?
首先,相似词的词向量也是相似的(下篇文章讲Word2Vec的时候会证明),在句子中替换相似词对结果的影响很小(输入相似,模型参数一定)。A cat is running in the room和A dog is running in the room可以获得相似的句子概率。
然后,预测结果肯定不会为0,自备平滑功能。
现在想想,我们最初的目标是训练一个神经网络语言模型,模型训练完成后,我们可以得到矩阵查找表(也就是词向量)和神经网络的模型参数。也就是说我们得到了两个产物。前者-词向量是本次模型训练过程中的副产物!而这些词向量具备我们之前说的特性:低维度稠密向量,可以通过距离度量词语相似度。这一点很重要,后面的Word2Vec正是来源于这个思想,这点下篇文章再说。
本小节的最后,还是来思考一下,当前这个神经网络语言模型有什么缺点吧:
- 模型输入为固定数量的上下文词语,无法获取更远词语的信息;
- 词表的大小一般都比较大,神经网络的输出层softmax函数的计算量会非常大,模型训练效率很低。
下一节和下篇文章介绍的模型将会解决这些缺点。
4. 循环神经网络语言模型
前面说过,神经网络语言模型由于使用的是全连接神经网络,其输入是定长的,所使用的上下文词语数量需要在模型训练前确定。因此在预测当前词时,该模型只能使用一定长度上下文的信息。为了解决该问题,Mikolov在2010年发表了论文《Recurrent Neural Network Based Language Model》,这篇论文中使用RNN替换全连接神经网络对语言模型进行建模。
这个模型的结构如下:
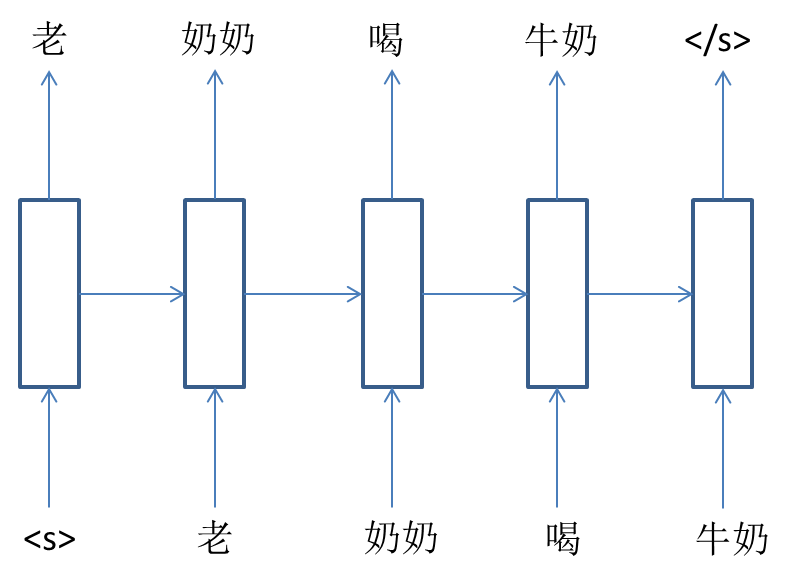
这个模型的思想就是通过使用RNN上一个时间步的隐层信息,代替距离当前词距离大于1的上下文词语的信息。
前面讲过,n-gram为了简化模型和方便计算,认为当前词语出现的概率只与前面有限几个词有关。而RNN语言模型则可以做到使用前面所有词的信息,又不使用海量的参数。但需要注意的是,RNN训练过程中存在梯度爆炸和消失问题,可能并不能获取过长距离的词语信息。此外,上一节中介绍的神经网络语言模型,其上下文使用的词向量具备一定的含义,而RNN使用上一时间步的隐层向量,其含义不甚明了。
5. 参考资料
- A Neural Probabilistic Language Model
- Recurrent Neural Network Based Language Model
- Word2Vec中的数学原理详解
- 知乎:深入浅出讲解语言模型
系列文章:
